ACTION-Net: Multipath Excitation for Action Recognition
单位 都柏林圣三一大学、字节跳动
会议 CVPR 2021
论文地址 arxiv
代码地址 github
摘要
时空特征、通道特征和运动特征是视频动作识别中三种重要信息。传统的二维CNN计算成本低,但无法捕捉时间关系;三维CNN可以很好捕捉时间关系,但计算量大。在这项工作中,通过设计一个通用且有效的模块来解决这个难题,该模块可以嵌入到二维CNN中。为此,提出了一种时空、通道和运动激励(ACTION)模块,包括三条路径:时空激励(STE)路径、通道激励(CE)路径和运动激励(ME)路径
STE路径采用单通道3D卷积来表征时空表示
CE路径通过在时间方面显式地建模通道之间的相互依赖性来自适应地重新校准通道特征响应
ME路径计算特征级的时间差,然后利用这些时间差来激励运动敏感通道
引言
视频中的复杂动作通常是时间相关的,它不仅包含每一帧的空间信息,而且还包含一段时间内的时间信息。传统的动作识别更多的是场景相关的,其中的动作没有时间依赖性,例如,“上眼妆”,“走路”,“跑步”。随着技术的飞速发展,如虚拟现实(VR)等需要利用特征与环境进行交互的技术,时间相关的动作识别近年来成为研究的热点。
现有方法的主流是基于三维CNN和基于二维CNN。3D CNN已被证明在时空建模方面是有效的,但时空建模无法捕获视频中包含的足够信息。提出的双流体系结构将时空信息和光流纳入计算,与单流体系结构相比显著提高了性能。然而,光流的计算非常昂贵,这给实际应用带来了挑战。三维CNN存在过拟合和收敛速度慢等问题。
随着更多大规模数据集的发布,如Kinetics、Moments in Time和ActivityNet,优化3D CNN变得更加容易和普及。然而,基于3D CNN固有的繁重计算导致推断速度缓慢,这将限制它们在实际应用中的部署,例如依靠在线视频识别的虚拟现实。当前基于2D CNN的方法有着轻量级和快速推理的优势。这些方法基于从整个视频中稀疏采样的一系列短片段(称为片段),最初在TSN中引入。原始的二维cnn缺乏时间建模能力,这导致在某些操作中丢失了必要的序列信息,例如“打开一个盒子”与“关闭一个盒子”。TSM通过在时间轴上移动一部分通道,将时间信息引入到基于2D CNN的框架中,这显著改善了基于2D CNN的框架的基线。然而,TSM仍然缺乏明确的动作时间模型,例如运动信息。
最近的工作根据ResNet架构将嵌入式模块引入到2d cnns中,具有运动建模的能力。为了捕捉视频中包含的多种类型的信息,以前的工作通常在输入级帧上进行。例如,SlowFast网络以多种速率对原始视频进行采样,以描述慢动作和快动作;双流网络利用预先计算的光流来推理运动信息。这种方法通常需要多分支网络,这需要昂贵的计算。
受上述观察结果的启发,提出了一种新的即插即用、轻量级的时空、通道和运动激励(ACTION)模块,通过采用多径激励在单个网络中有效地处理特征层上的多种类型信息。时空特征和运动特征的组合可以类似地理解为双流结构,但是基于特征级别对网络内部的运动进行建模,而不是生成另一种类型的输入(例如,光流)来训练网络,这大大减少了计算量。受SENet的启发,基于时域提取通道特征来表征网络的通道相关性。相应地,配备了这样一个模块的新体系结构被称为ActionNet。
相关工作
基于 3D CNN
基于3D CNN的框架具有时空建模能力,提高了视频动作识别的模型性能。I3D将ImageNet预先训练的2D核膨胀为3D核,用于捕获时空信息。为了更好地表示运动模式,I3D利用了预先计算的光流和RGB(也称为双流结构)。SlowFast 网络被提出用于处理视频中动作的不稳定速度,例如跑步和步行,它分别涉及一个慢分支和一个快分支来模拟慢动作和快动作。尽管基于3D CNN的方法在多个基准数据集上取得了令人兴奋的结果,但它们包含大量参数。
在这种情况下,会产生各种各样的问题,例如容易过度拟合和难以收敛,这带来了挑战,包括在真实应用中在线流视频的低效率的推断。尽管最近的工作已经证明三维卷积可以分解以在一定程度上减少计算,但是与基于二维CNN的框架相比,计算仍然是一个更大的负担。
基于2D CNN
TSN是第一个提出的将2D CNN应用于视频动作识别的框架,该框架引入了“片段”的概念来处理视频,即使用单一形式的稀疏采样方案在长视频序列上提取短片段。然而,直接使用2dcnns缺乏对视频序列的时域建模。TSM首先将时态建模引入到基于二维CNN的框架中,将一部分通道的移位操作嵌入到二维CNN中。然而,TSM缺乏明确的动作时间建模,例如相邻帧之间的差异。最近,有几项工作建议将模块嵌入到二维CNNs中。这些模块能够模拟运动和节奏信息。例如,MFNet、TEINet和TEA引入了这种类型的模块,它们在ResNet架构上被证明是有效的。STM提出了一种用于时空和运动信息建模的块,而不是普通的残差块。GSM利用组空间选通来控制时空分解中的交互。
SENet 和改进
Hu等人介绍了一种SENet体系结构。提出在二维CNN中嵌入squeeze-and-excitation(SE)块。在这种情况下,通过显式地建模通道相互依赖性,可以增强有关图像识别任务的通道特征的学习。为了解决这个问题,SE块以squeeze-and-unsqueeze方式利用两个全连接的层,然后应用Sigmoid激活函数来激发基本的通道特性。但是,它独立地处理每个图像,而不考虑关键信息,如视频的时间特性。为了解决这个问题,TEA引入了运动激励(ME)和多重时间聚集(MTA)来捕捉短期和长期的时间演化。需要注意的是,MTA是专门为Res2Net设计的,这意味着TEA只能嵌入Res2Net中。受前两个工作的启发,提出了STE和CE模块,解决时空和通道在时间维度上的相互依赖性。Action模块由STE、CE和ME并行组装而成,可以激活视频中的多种类型信息。
ACTION的设计
ACTION模块由时空激励(STE)、通道激励(CE)和运动激励(ME)三个子模块组成
整体ACTION模块分别对STE、CE和ME生成的三个激励特征进行元素级的相加。通过这样做ACTION模块的输出可以获得时空信息、通道间依赖信息和运动信息。图3显示了ResNet-50的ACTION-Net架构,其中ACTION模块插入到每个残差块的开头。它不需要对块中的原始组件进行任何修改。
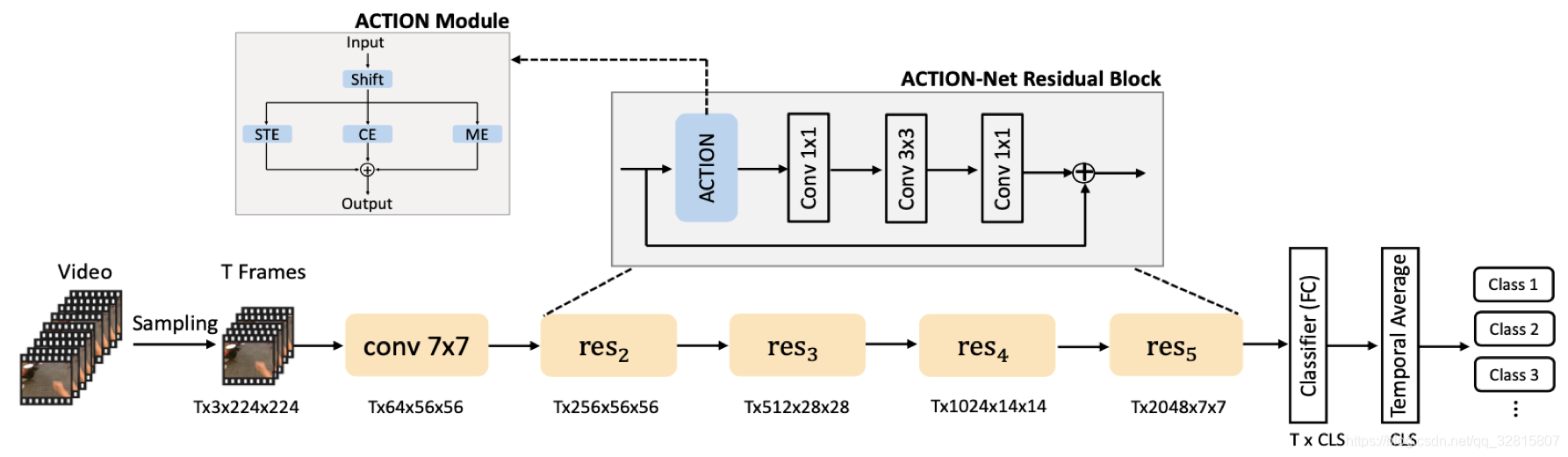
时空激励 (STE)
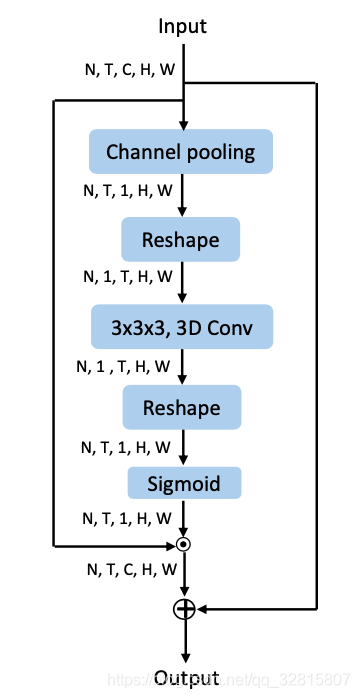
对输入X (N×T×C×H×W)通道平均池化得到F(N×T×1×H×W)
改变F维度为N×1×T×H×W
经过3×3×3的3D卷积中得到$F^∗ (N×1×T×H×W)$
将$F^∗$ 改变维度得到$F_o (N×T×1×H×W)$
$F_o$ 经过Sigmoid激活得到mask M(N×T×1×H×W)
输入X经过M⨀X+X激励得到输出
通道激励(CE)
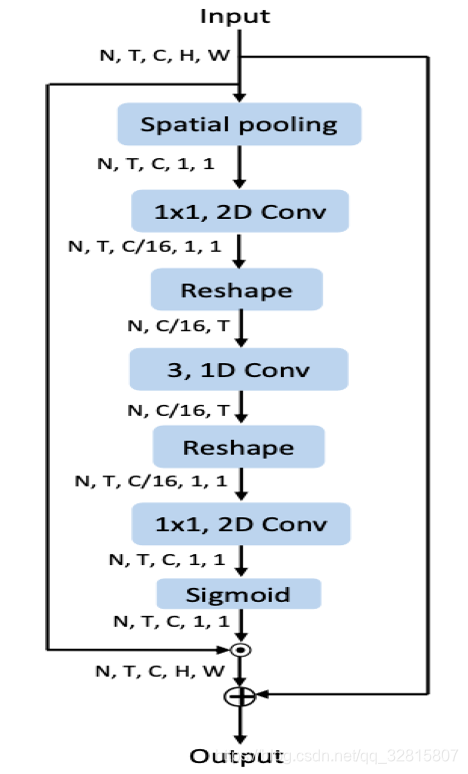
对输入X (N×T×C×H×W)在空间平均池化得到F(N×T×C×1×1)
使用1×1卷积来压缩 F的通道数得到特征 $F_r (N×T×C/r×1×1)$
改变 $F_r$ 维度得到$F_r^{*} (N×C/r×T×1×1)$
经过卷积核为3的一维卷积后得到 $F_{temp}^{*} (N×C/r×T×1×1)$
改变$ F{temp}^{*}$ 维度为 $F{temp} (N×T×C/r×1×1)$
经过1×1卷积得到$ F_o (N ×T ×C ×1 ×1) $
$F_o$经过Sigmoid激活,得到mask M(N ×T ×C×1×1)
输入X经过M⨀X+X激励得到输出
运动激励(ME)
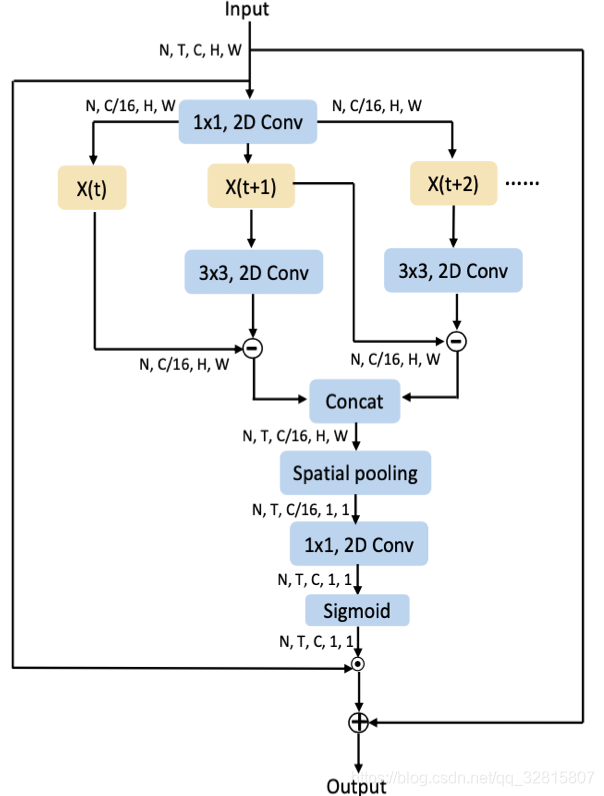
输入X (N×T×C×H×W)经过1×1卷积压缩得到 $F_r (N×T×C/r×H×W)$
计算各帧的运动特征 K是3×3卷积
$F_m=K∗F_r [:,t+1,:,:,:]-F_r [:,t,:,:,:]$
根据时间维度将运动特征串联得到$F_M (N×T×C/r×H×W)$
$F_M=[F_m (1),⋯,F_m (t-1), 0]$
$F_M$经过空间平均池化得到$F_o (N ×T ×C/r×1 ×1) $
再经过1×1卷积, Sigmoid激活后得到mask M
输入X经过M⨀X+X激励得到输出
实验
数据集
| 数据集 | 介绍 | 行为数 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|---|
| Something-Something V2 | 人与日常生活中物体交互的动作数据集 | 174 | 168,913 | 24,777 | 27,157 |
| Jester | 第三人称视角的手势数据集 | 27 | 118,562 | 14,787 | 14,743 |
| EgoGesture | 头戴式摄像机记录的手势数据集 | 83 | 14,416 | 4768 | 4977 |
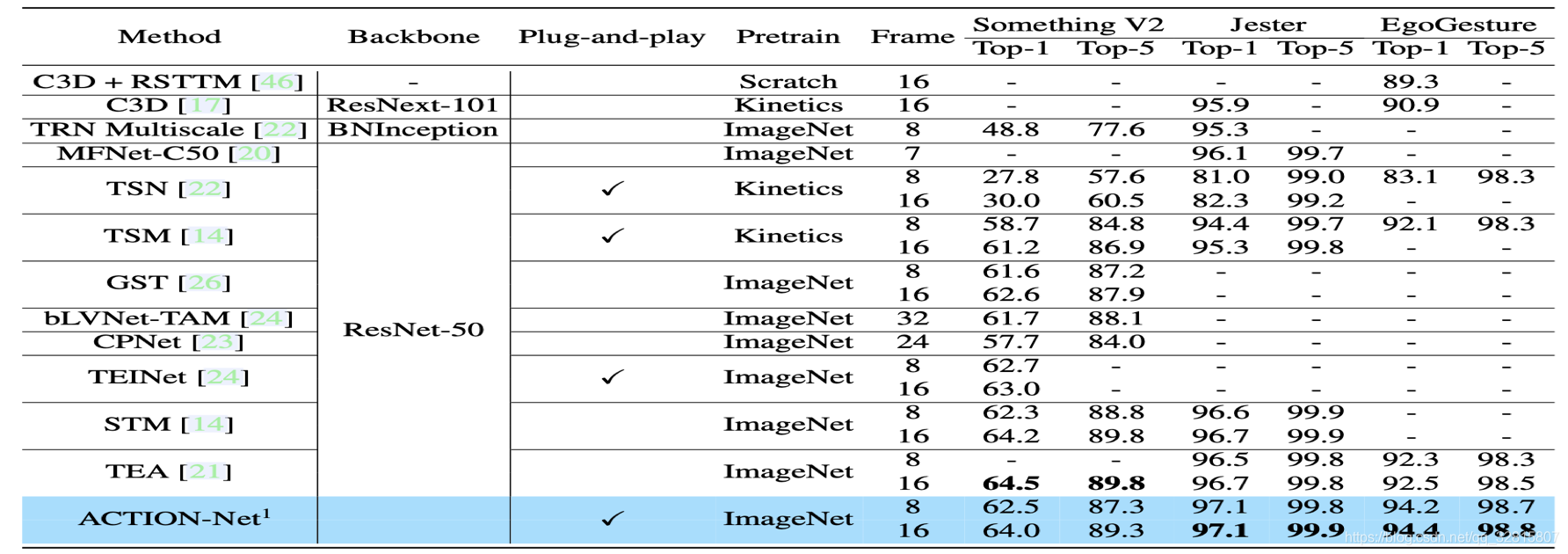
在Jester和EgoGesture上取得了SOTA
在Something V2上相比较STM和TEA也取得了接近的效果
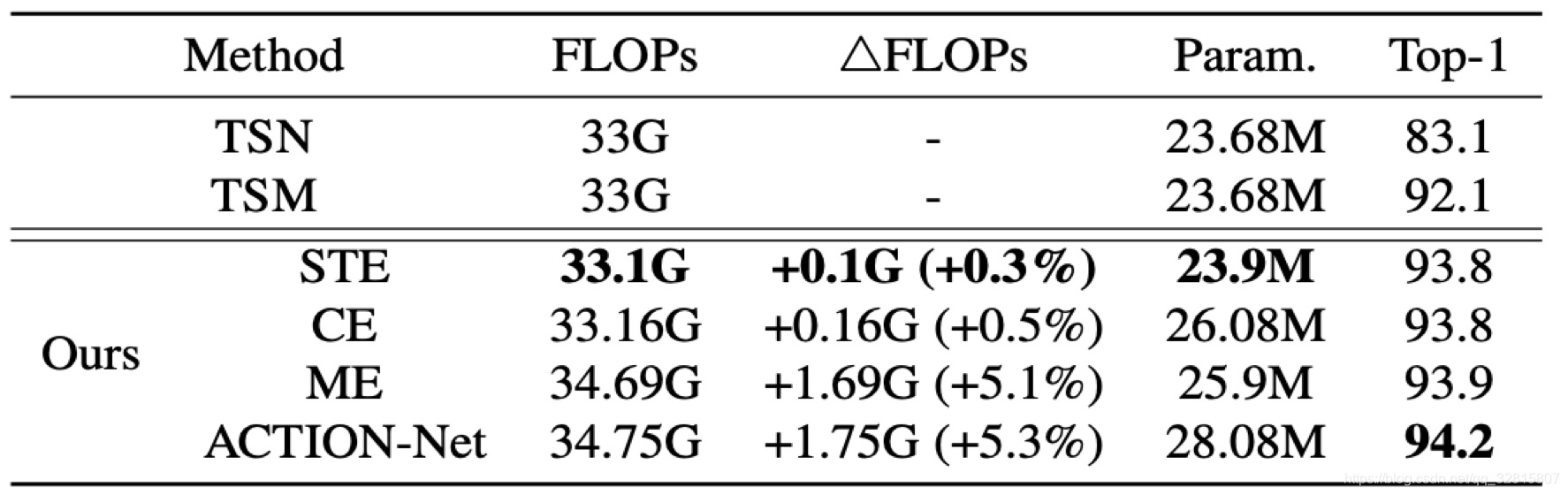
消融实验
动作激励相比时空激励和通道激励对性能提升最大
时空激励在更小的计算量和参数量下性能提升和通道激励相当
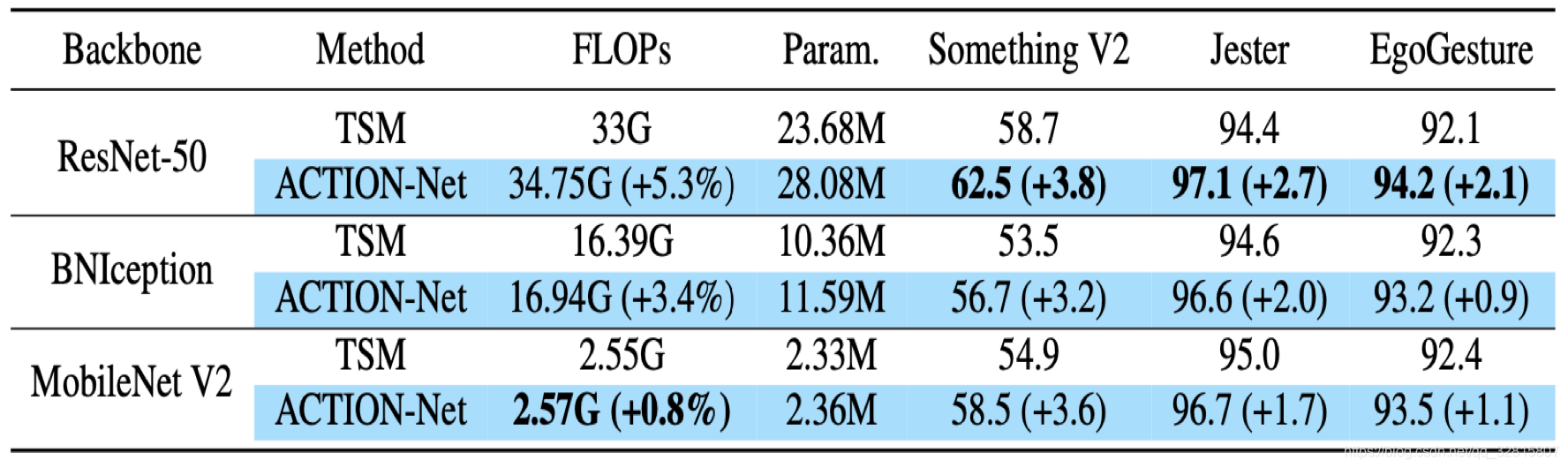
ACTION-Net在不同主干网络都带来了性能提升,具有良好的通用性
总结
- 提出了一个即插即用、轻量级的时空、通道和运动激励模块(ACTION)
- 采用了多路径激励的方法有效地捕获时空特征、通道特征和运动特征
- 提出的ACTION模块可以被任何二维卷积模型用来构建视频动作识别网络